


基于roban_whole_body_tracking的强化学习实践经验分享

physicalbutter
强化学习理论学习
- 强化学习网课推荐:赵世钰的强化学习网课,用数学的方式讲述强化学习的原理,视频相较于其教材简化了许多。看完后会对强化学习的运行框架有更清晰且深入的认知,学习者会学到什么是MDP、什么是rewards/policy/value、PPO的理论依据是什么,这些是后续强化学习(RL)的基础。
- 论文推荐:
- Humanoid-Gym 讲述了一个完整、可拓展的强化学习框架,篇幅较短,流程相对完整。在了解RL的基础后,这篇论文可以引导读者关注人形机器人的RL怎么真正落地。
- Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning 关注的是如何将传统的基于模型的脚步规划和RL结合起来,用于实现更稳定可控的腿式行走。论文篇幅适中,没有追求新的RL算法,而是通过一种“模型给予目标、RL学习执行”的分层结构来让RL更好地落地,适合具备一定强化学习和机器人动力学基础的读者阅读。
- Beyondmimic 关注的是使用RL来实现动作跟踪(Mimic),论文从传统的动作模仿出发,进一步提升人形机器人在动作多样性和任务泛化方面的能力。论文篇幅适中,是Mimic训练框架
whole_body_tracking的理论基础,推荐配合代码理解论文。下文将提供基于whole_body_tracking进行实操来实现动作跟踪的流程与经验。 - AMP 这篇论文提供了一种基于对抗性动作先验的方法,通过学习数据的风格,来让物理仿真角色(包括机器人和虚拟人物)的动作更自然、多样。论文篇幅适中,配合有开源代码。对于已经具备一定RL与运动模仿基础的读者,这篇工作可以帮助理解如何用数据驱动的方式生成更丰富、更真实的动作表现,而不依赖传统的手工目标设计。
基于leju-gmr和roban_whole_body_tracking进行Mimic实操
Tips: 以下内容推荐对于 leju-gmr 和 roban_whole_body_tracking 有过实操经验的朋友参考,内容偏向经验分享而非完整流程教学。
1. 基本流程
整个流程分为数据准备、训练和部署三个阶段。数据准备阶段需要将bvh格式的动作数据转换为npz格式,训练阶段使用转换好的npz文件进行强化学习训练,部署阶段可以在仿真和实际环境中测试训练动作效果。
数据准备流程:
- 录制动捕数据:此处需要导出数据为
.bvh格式,后续使用leju-gmr工具将bvh数据映射到机器人上。 - 数据流向与格式转换:
- bvh(数据格式,包含骨骼数据和关节的相对位姿数据,即原始动捕数据,可以扔给ai分析) -> GMR(retarget重定向工具,将人体数据通过缩放等操作映射到机器人上) -> pkl(数据格式,包含机器人baselink的全局位姿和关节角度数据)
- pkl -> csv(数据格式转换,需要注意数据顺序处理,包括四元数顺序与关节顺序)
- csv -> isaacsim(仿真器) -> npz(数据格式,包含很多奖励函数需要的全局位姿,速度角速度等更丰富的数据)
- npz -> csv(数据格式转换,用于部署,数据只包含观测需要的关节位置和速度)
注意: 前两步的转换脚本在
leju-gmr中,后两步在roban_whole_body_tracking中。
训练流程:
准备好npz文件后,使用 scripts/rsl_rl/train.py 进行训练,训练配置在 source/whole_body_tracking/whole_body_tracking/tasks/tracking/config/roban_s2/ 目录下,主要包括环境配置和PPO算法配置。
部署流程:
使用部署代码进行部署,部署时着重关注配置文件,确保机器人使用的Kp和Kd等参数与训练时一致。若使用 kuavo-ros-opensource(opensource/roban_factory分支) 进行部署,配置文件便是 src/humanoid-control/humanoid_controllers/config/kuavo_v${机器人版本}/rl/skw_rl_param.info。
2. 理解代码框架
代码框架基于 IsaacLab,主要分为几个部分:机器人定义、环境配置、奖励函数、观测和动作空间。
- 机器人定义:在
robots/roban_s2.py,定义了机器人的URDF、关节配置、电机参数等。 - 环境配置:在
tasks/tracking/tracking_env_cfg.py,包括场景设置、域随机化参数、奖励函数配置等。 - 奖励函数:在
tasks/tracking/mdp/rewards.py,定义了各种跟踪奖励和惩罚项。 - 观测和动作空间:在
tasks/tracking/mdp/observations.py和actions.py中定义。
训练时使用的是 ManagerBasedRLEnv,通过 command_manager 来管理动作命令,reward_manager 来管理奖励计算。动作命令 MotionCommand 会从npz文件中读取参考轨迹,机器人需要跟踪这个轨迹。
3. 原始数据处理
数据处理中最容易出问题的是帧率和格式转换:
-
单位换算:动捕数据(.bvh)重定向并输出为轨迹文件(.pkl)时要注意动作数据的单位换算。默认需要将数据从 mm(动捕数据单位)转换为 m(pkl期望单位),即数值除以1000。有的动捕数据使用的单位是cm,那就需要在代码中修改,将除以1000改为除以100。
-
帧率设置:csv转npz(通过isaacsim)时要注意
input_fps和output_fps的设置。动作轨迹的流速只与input_fps有关,output_fps决定输出的帧数,这通常由仿真器的帧数决定。如果input_fps设置过小,即轨迹流速太慢,动作卡顿的情况。 -
调优建议:通常情况下推荐csv转npz(通过isaacsim)时
input_fps与bvh的原始数据帧率一致,便于发现问题和找到改进方向。如果发现以原速度训练出来的保持慢平衡的效果较差,可以考虑提升input_fps,将轨迹加速;如果发现机器人速度过大、动作跳脱,则考虑降低input_fps,将轨迹减速。
4. 奖励函数设计
奖励函数设计是训练的关键,需要平衡跟踪精度和稳定性。基本的跟踪奖励包括关节位置跟踪、关节速度跟踪、身体部位位置和姿态跟踪。
基础跟踪奖励函数(指数形式):
其中,e 是跟踪误差(位置误差、姿态误差或速度误差),σ 是标准差参数,控制奖励衰减的速度。误差越小,奖励越接近1;误差越大,奖励越接近0。
本文不讨论一些基础的奖励函数,而是总结一些个人在训练过程中针对特定情况作出特殊处理的经验。
4.1 关于末端跟踪
在动作跟踪训练中,额外关注末端的跟踪情况通常是有效的。对于双足人形机器人,通常选取手部和脚部作为末端进行额外跟踪。
-
起初笔者按照惯例对手和脚进行额外跟踪奖励,tracking_env_cfg.py 中的配置如图所示:

sim2sim效果如视频-跟踪脚部所示(下有简易GIF以便浏览)。通过sim2sim的效果可以发现,对于单双脚替换的动作轨迹,额外关注脚部跟踪可能会导致机器人踉跄,尤其在后半段。

-
为解决这一问题,笔者实验性地不额外关注脚部,而去跟踪小腿。修改跟踪脚部的奖励函数为跟踪小腿的奖励函数,至于脚部,则让其在RL中自适应训练即可。tracking_env_cfg.py 中的配置如图所示:

发现sim2sim时的运动效果有所改善,如视频-跟踪小腿所示(下有简易GIF以便浏览)。

4.2 关于抬腿动作
由于RL的核心通常是“不倒”,所以抬腿这种动作机器人其实是极其不乐意学习的。观察上文附上的视频效果可以发现,机器人在运动过程中抬腿幅度不足。为了解决这一问题,笔者作为初学者作出了以下尝试(这些尝试最终因为逻辑漏洞而失败):
尝试一:
让机器人在单腿站立时,额外奖励大腿的跟踪。
这一奖励看似可以合理地让机器人抬起腿来,但其实这会变相鼓励机器人进行小幅度的踏步,以进入“单脚站立”这一状态,从而使得跟踪大腿获得更多的奖励。这导致了机器人不断踏步,是不恰当的改动。
尝试二:
添加触地惩罚函数,其判断条件是脚底板的高度大于高度阈值(lift_height_threshold)且接触力大于触地阈值(contact_threshold)。其在 rewards.py 中的设置如图所示:
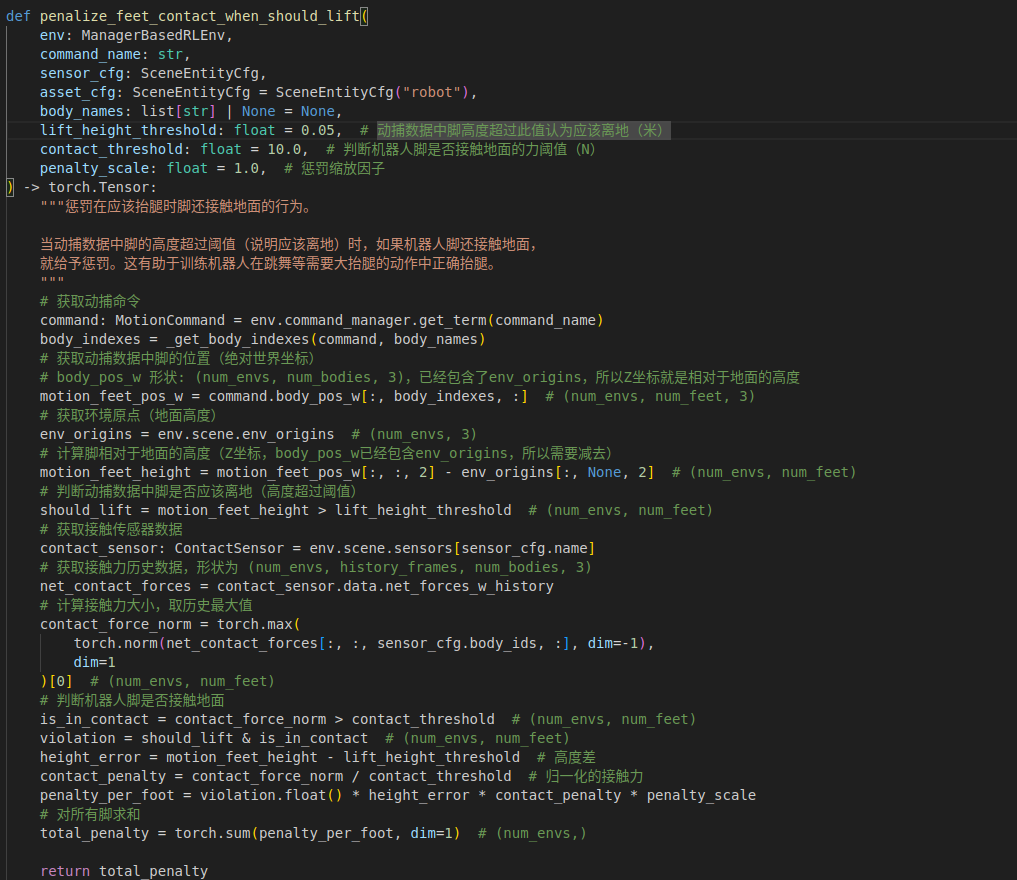
其中 lift_height_threshold 要根据动作数据来定,除了明显抬腿的帧数区间外,还有其他相对小幅度的抬腿区间,要根据这部分数据来定制。
- 起初,使用5cm(大概判断得出)作为高度阈值,效果如视频-5cm所示(下有简易GIF以便浏览)。发现机器人虽然仍有明显的蹭地现象,但抬腿效果已有所改善,说明这一调整方向可能是正确的。

- 进一步的,将高度阈值改成3cm(通过数据统计得出),效果如视频-3cm所示(下有简易GIF以便浏览)。发现机器人抬腿效果有所改善,蹭地行为也明显减少,但是动作并不流畅,有些卡顿。这种不流畅在sim2sim中还不太明显,但在sim2real中却会造成难以接受的运动效果,因此这一改动不能算是成功。

经验总结: 通过这两个不太成功的尝试,笔者想要分享在设计奖励函数时的体会:
- 一个奖励或者惩罚,如果它贯穿全程,那么这一奖励在影响你预期的部分外,还会影响其他部分,从而造成一些难以排除的不良效果(如踏步)。
- 如果这个奖励或惩罚只在某一区间有效,那么这种不连续很可能导致机器人运动不自然。例如,当脚的期望高度低于3cm时,机器人为了稳定会保持脚着地;而当期望高度达到3cm时,动作又会发生猛然跳变。这种出于对问题浅层理解而设计的奖励函数或许能暂时起效,但不仅增加了复杂度,也无法解决根本问题。如果一定要添加一个奖励函数,我们期望这个奖励函数能触及问题根本。
4.3 奖励质心的跟踪
-
吸取前面两次不恰当的尝试后,我们需要进一步解剖机器人不抬腿这一问题。机器人不抬腿,可以看作是机器人在害怕摔倒和需要跟踪轨迹之间挣扎的结果。要想解决这一问题,可以鼓励机器人不摔倒,从而让机器人的平衡效果更稳定,进而能更好地去跟踪轨迹。而在慢平衡的情况下,机器人摔倒或者踉跄,很可能就是质心跟踪问题。
-
为了验证这一点,我们尝试将机器人的运动轨迹流速加快至1.5倍,以加快质心转移的速度,效果如视频-1.5倍所示,从这一步开始,机器人可以进行sim2real的测试(下有简易GIF以便浏览)。

-
接着,使用质心跟踪奖励函数,根据机器人的支撑情况奖励质心平衡,其在 rewards.py 中的设置如图所示:
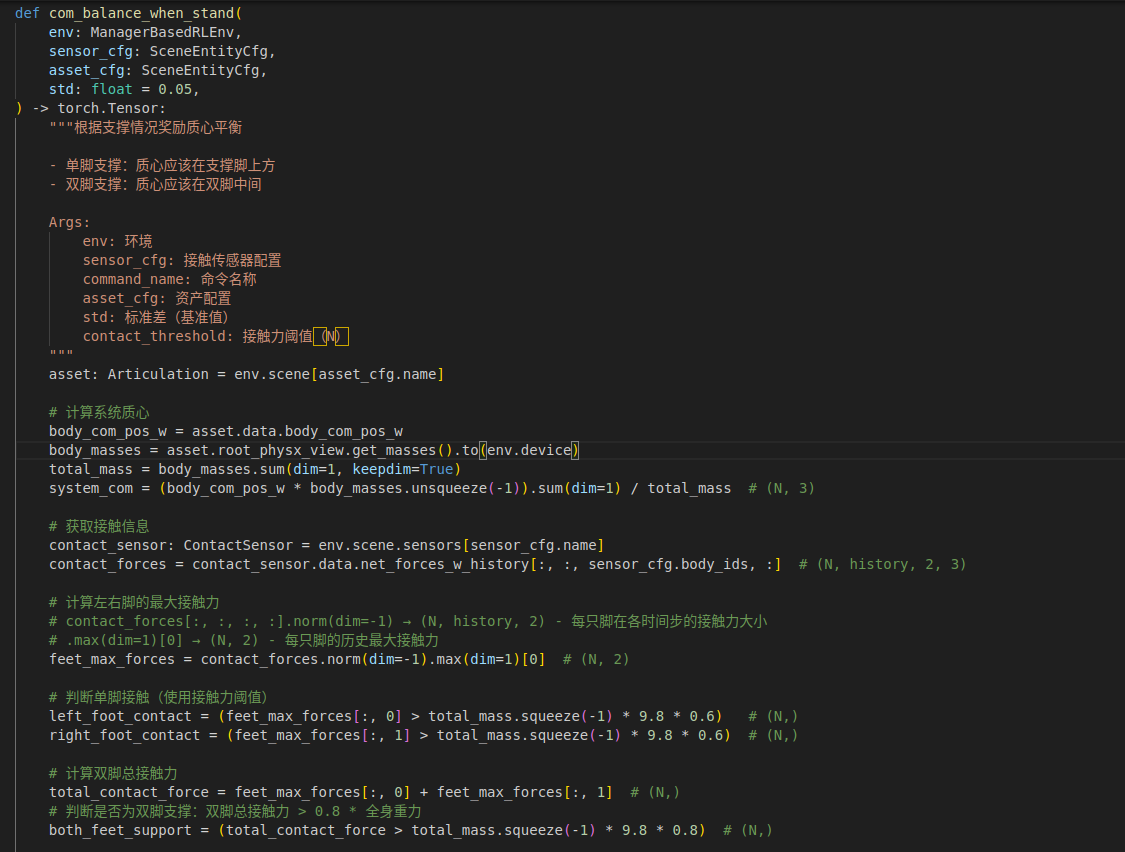
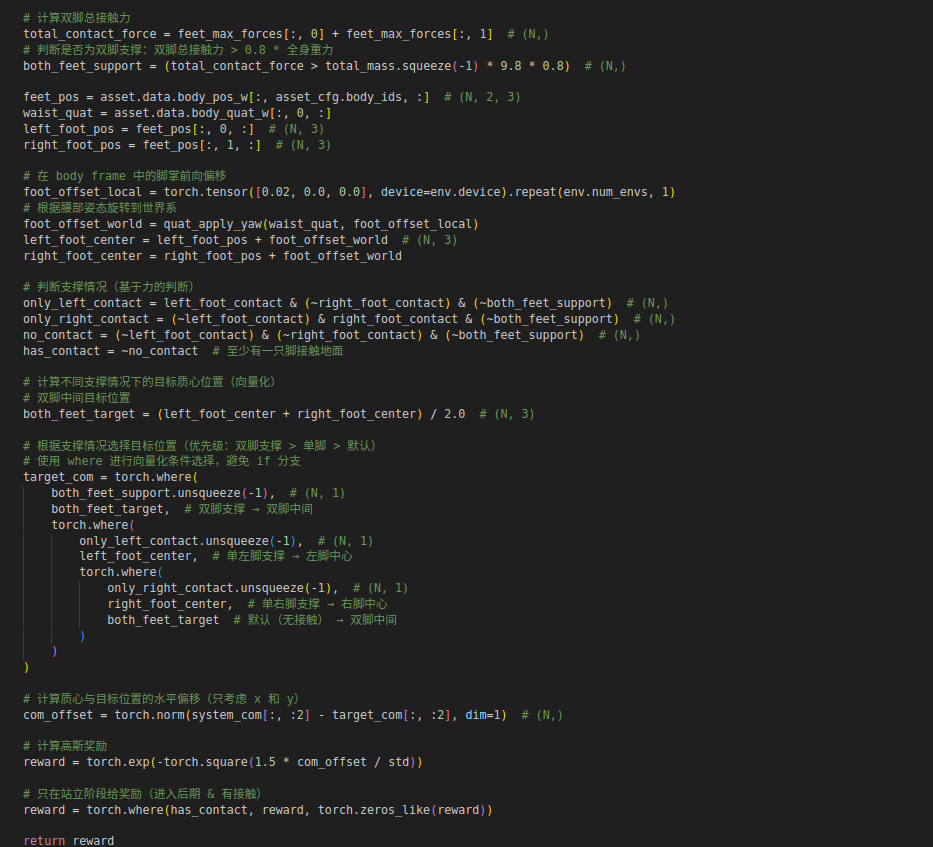
该奖励函数的核心思想是:根据机器人的支撑状态(单脚支撑或双脚支撑),动态设置目标质心位置,然后奖励机器人将系统质心保持在目标位置附近。这个函数的设计基于一个简单的物理原理:单脚支撑时,质心的水平投影(x和y坐标)应该在支撑脚的水平投影位置上方(或重合)才能保持平衡;双脚支撑时,质心的水平投影应该在双脚中间才能稳定。
-
这个函数的设计有几个优点: 首先,它不依赖动捕数据,完全基于物理状态(接触力和质心位置),这使得它能够适应不同的动作;其次,它动态地根据支撑状态调整目标,比固定目标更合理;最后,它只考虑水平方向的偏移,符合平衡控制的物理原理。
-
这一改动的sim2sim效果如视频-追踪质心所示(下有简易GIF以便浏览)。发现机器人运动效果明显改善,但是因为质心跟踪权重不当,导致机器人动作有些变形。后续只需调整质心跟踪的权重,就可以中和这一矛盾。

5. 域随机化
在上文的基础上,考虑基于基础的域随机化进行修改和添加。
域随机化用于提高sim2real的泛化能力。主要包括推力随机化、质心随机化、摩擦系数随机化等,此处针对训练过程中出现的问题分享一些尝试:
-
面对机器人实机踉跄的问题,加大域随机化的推力,可以让机器人适应外界的干扰,其在 tracking_env_cfg.py 中的配置如图所示:
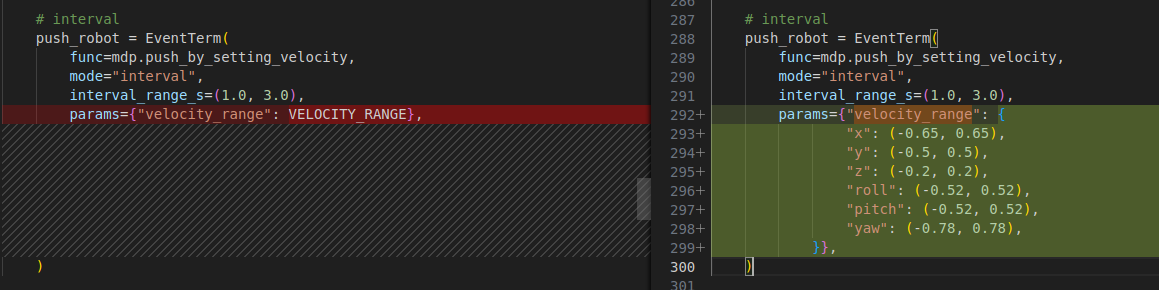
效果如视频-加大推力所示(下有简易GIF以便浏览)。

-
如果出现机器人静止时不断晃动的问题,可以将质心随机化的范围缩小,这能让机器人学会稳定地站住不晃动。
6. 其他细节处理
6.1 训练参数配置(kp、kd与scale)
训练参数配置非常重要,尤其是位置刚度系数(K_p)和阻尼系数(K_d)。以下是相关的基准计算公式:
1. 电机控制器的scale与kp的关系:
其中,T_limit 是电机的力矩限制,K_p 是位置刚度系数。
2. kp和kd的理论计算公式(基于动力学论文):
变量说明:
- I_j 为电机的转动惯量乘以减速比的平方,即
- ω_n 为自然频率
- ζ 为阻尼比
6.2 动作输出(Action)处理与缩放
1. 网络输出的ACTION_SCALE计算公式:
其中,i 表示第 i 个关节,effort_limit 是该关节的力矩限制,stiffness 是该关节的刚度系数。
2. Action的具体处理公式:
变量说明:
- q_target 是最终的目标关节位置向量
- a_raw 是网络输出的原始action向量(残差量)
- s 是ACTION_SCALE向量,
- ⊙ 表示逐元素相乘(Hadamard积)
- q_motion 是动捕数据中当前时间步的参考关节位置向量
参数调优建议:
scale、kp和kd可以以上述公式计算结果作为 baseline(基准值),具体操作中可以在此基础上进行微调。
- 修正能力与实机差异: 如果
ACTION_SCALE数值过小,可能导致网络的修正能力弱。在面对实机与仿真的差异时,机器人需要足够的修正量才能在实机上达到和仿真一样的效果(表现出来是机器人在仿真中正常,在实机里关节较软),所以需要保证ACTION_SCALE数值不太小。 - 避免过大: 但
ACTION_SCALE也不应该过大,过大很可能导致动作不稳定和训练困难的问题。
6.3 数据与模型调优经验
- 裁剪初始帧防跳变: 另外要注意csv文件的头几帧,如果部署时机器人一开始就跳变或者异常抖动,可能是数据前几帧的重定向效果不好,可以考虑 删掉前几帧 看看效果是否改善。
- GMR锚点稳定重心: 如果重心变化过快,可以在gmr时,给机器人的xml文件 添加两个锚点。位置设为脚踝外侧,使脚更加内靠,重心变化幅度更小。但这样操作引入的变量有些多,需要谨慎测试。