

数据采集与ACT模型推理效果优化经验分享

硅基生命训练师
本文是对 具身智能数据处理与模型训练框架 莫吉托酒调制 和 果蔬分拣 场景实现的经验分享
1. 数据采集过程优化
1.1 数采注意事项
采集的数据应尽量平滑流畅,应避免出现停顿、反复的动作,比如重复摇晃这类的动作,这对操作者的熟练度会有一定的要求。例如仓库中ACT策略默n_obs_steps=1,即观测步数为1,如果模型训练时加入了停顿、反复等动作,部署推理时向模型输入相同的观测值,模型会无法判断下一步应该执行停顿还是退出,容易产生歧义,导致动作最终表现为循环执行一个动作或停顿卡死。
1.2 机器人手臂与头部零点的影响
零点本质上是「关节角读数相对哪一姿态为 0」的约定,一旦变了,整条数据管线里的数都会跟着变。数采和模型部署的过程:机器人手臂与头部零点若变化较大,会导致执行同一物理动作,记录的关节角整体平移,并且会影响头部相机与手腕相机记录的图像数据。零点不一致会在数据里引入隐藏偏置,模仿学习会学到错误或混杂的映射,导致样本效率变差。
1.3 机器人躯干姿态的影响
笔者在数采时,发现机器人每次站立后的躯干姿态会稍有不同,主要体现在pitch俯仰角度的差异上。通过读取机器人两次站立后的/sensors_data_raw 话题数据中的imu_data.quat字段,也可以观测到这一现象。
| 序号 | Quaternion (x, y, z, w) | Roll (°) | Pitch (°) | Yaw (°) |
|---|---|---|---|---|
| 1 | (-0.00338, 0.02827, -0.04019, 0.99879) | -0.26° | 3.25° | -4.60° |
| 2 | (-0.00257, 0.00601, -0.11551, 0.99329) | -0.21° | 0.72° | -13.26° |
两次站立 imu pitch(前后俯仰)相差约2.53°,反应到手臂末端执行器的位姿误差会被放的更大。
优化方案:
向/cmd_pose话题发布全零数据,控制机器人姿态归位,提高机器人数据采集时身体姿态的一致性
rostopic pub /cmd_pose geometry_msgs/Twist "linear:
x: 0.0
y: 0.0
z: 0.0
angular:
x: 0.0
y: 0.0
z: 0.0"
两次站立并发布空信息后读取 /sensors_data_raw
| 序号 | Quaternion (x, y, z, w) | Roll (°) | Pitch (°) | Yaw (°) |
|---|---|---|---|---|
| 1 | (-0.00352, 0.00676, -0.04029, 0.99916) | -0.37° | 0.79° | -4.62° |
| 2 | (-0.00274, 0.00572, -0.11595, 0.99323) | -0.24° | 0.69° | -13.32° |
通过向向/cmd_pose话题发布全零数据,pitch差异缩小到0.1°。
优化方案总结:
笔者在实现场景的过程中形成一个约定,在每次进行数据采集和部署推理前:
-
执行一次 零点自动标定程序
利用机械限位作为物理基准,通过受控转动使头部和手臂关节到达标定姿态并写入零点,提高零点一致性。 -
执行完自动标定,在机器人正常站立后,笔者会向
/cmd_pose话题发布全零数据,提高机器人数据采集时身体姿态的一致性。
2. 数据检查与训练日志
2.1 数据重放
在数采和部署推理过程中,若是想检查机器人身体姿态是否发生变化?站位是否一致?可以重放采集的rosbag包,观察机器人手臂执行的位置是否符合预期。
2.2 Rosbag数据检查
采集的Rosbag数据集,可以通过Foxglove等可视化工具打开,拖动进度条观察播放是否正常,三个相机的图像数据是否正常,各个话题数据帧率是否符合预期。
以下是Rosbag包中应该包含的完整话题列表,各个话题数据帧率应该高于检查帧率。
| Topic | 描述 | 帧率检查 |
|---|---|---|
/cam_h/color/camera_info |
头部彩色相机参数 | 25Hz |
/cam_h/color/image_raw/compressed |
头部彩色压缩图像 | 25Hz |
/cam_h/color/metadata |
头部彩色元数据 | 25Hz |
/cam_h/depth/camera_info |
头部深度相机参数 | 25Hz |
/cam_h/depth/image_raw/compressedDepth |
头部深度压缩图像 | 25Hz |
/cam_h/depth/metadata |
头部深度元数据 | 25Hz |
/cam_l/color/camera_info |
左腕彩色相机参数 | 25Hz |
/cam_l/color/image_raw/compressed |
左腕彩色压缩图像 | 25Hz |
/cam_l/color/metadata |
左腕彩色元数据 | 25Hz |
/cam_l/depth/camera_info |
左腕深度相机参数 | 25Hz |
/cam_l/depth/image_rect_raw/compressedDepth |
左腕深度压缩图像 | 25Hz |
/cam_l/depth/metadata |
左腕深度元数据 | 25Hz |
/cam_r/color/camera_info |
右腕彩色相机参数 | 25Hz |
/cam_r/color/image_raw/compressed |
右腕彩色压缩图像 | 25Hz |
/cam_r/color/metadata |
右腕彩色元数据 | 25Hz |
/cam_r/depth/camera_info |
右腕深度相机参数 | 25Hz |
/cam_r/depth/image_rect_raw/compressedDepth |
右腕深度压缩图像 | 25Hz |
/cam_r/depth/metadata |
右腕深度元数据 | 25Hz |
/joint_cmd |
关节指令 | 25Hz |
/kuavo_arm_traj |
机械臂轨迹 | 25Hz |
/sensors_data_raw |
原始传感器信息 | 25Hz |
/tf |
坐标变换 | 25Hz |
/tf_static |
静态坐标变换 | -1 |
/control_robot_hand_position |
手部位姿 | 25Hz |
/dexhand/state |
灵巧手信息 | 25Hz |
/leju_claw_command |
夹爪控制指令 | 25Hz |
/leju_claw_state |
夹爪状态 | 25Hz |
2.3 Lerobot数据检查
进入 kdc_dev 环境,进入数据转换后Lerobot数据集所在目录。
终端执行:
lerobot-dataset-viz --repo-id lerobot/pusht --root ./lerobot --mode local --episode-index 0
可以打开 Rerun 可视化客户端,回放检查数据转换后的Lerobot数据集。更多数据集工具使用方法可以参考 LeRobot官方文档
2.4 训练日志
进入 kdc_dev 环境,进入 kuavo_data_challenge 主目录。
终端执行:
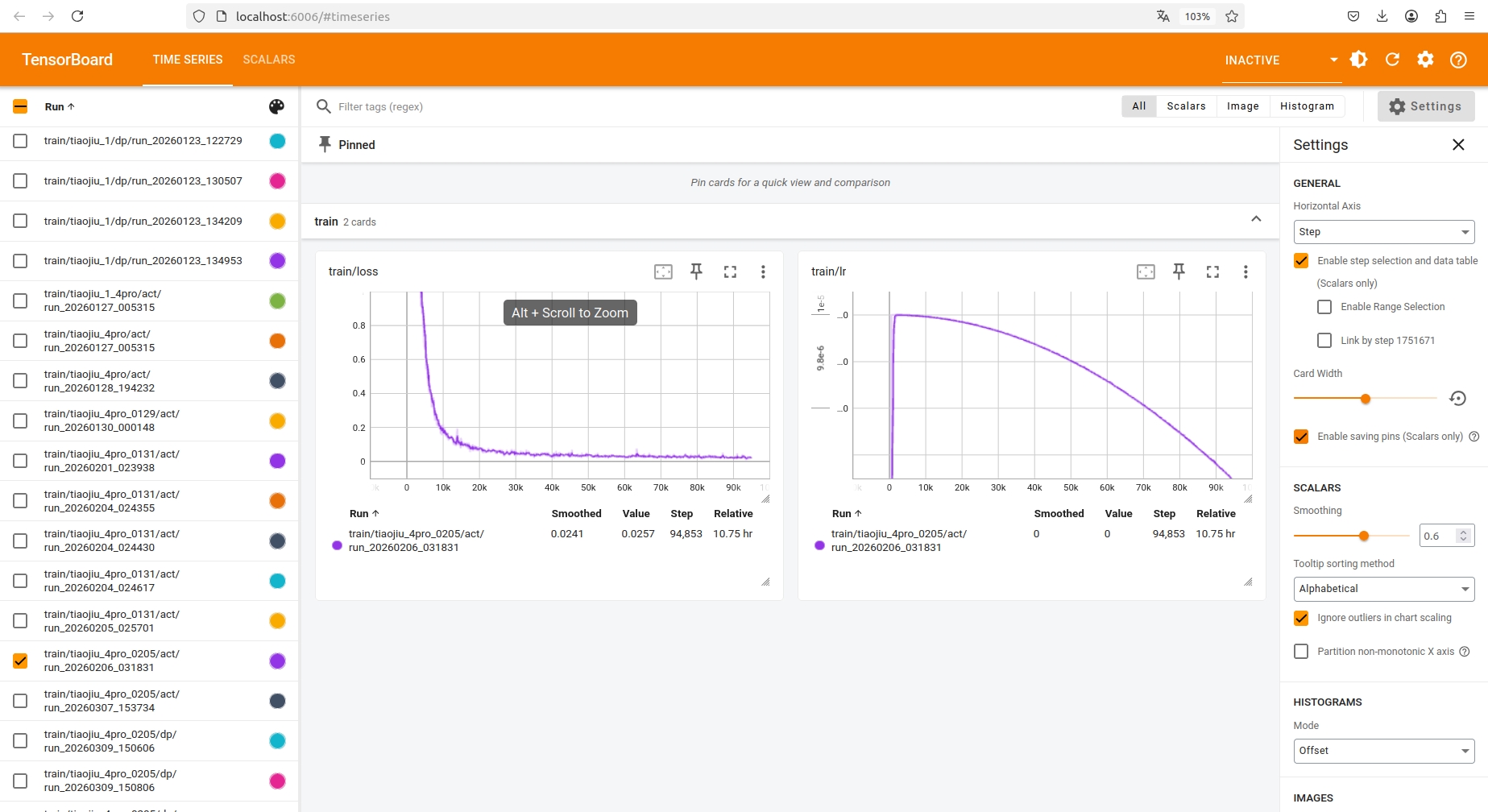
tensorboard --logdir outputs
用 tensorboard 可视化工具可以实时监控模型训练的 train/loss训练损失曲线 和 train/lr学习率曲线 ,观察训练是否收敛,ACT模型loss需要下降到0.1~0.01左右。
3. 动作下发优化:WBC 轨迹直控与动作平滑处理
笔者在使用
kuavo_deploy/eval_kuavo.py进行真机ACT模型同步推理的时候,发现表现与预期不相符,手臂执行的精度不高,幅度偏小。比如在 莫吉托酒调制 场景,机器人右手无法下降到足够高度去抓取柠檬,即使抓取到柠檬了,也无法移动到酒杯正上方,而是偏右。
后续笔者发现虽然模型输出通过 kuavo-humanoid-sdk 是直接向 /kuavo_arm_traj 话题发布手臂位置运动数据,但kuavo机器人在默认情况下,WBC 最终拿到的手臂参考来自 MPC。MPC 通常会惩罚大速度/大加速度/大偏差,同时受机器人全身稳定、约束(关节/接触/稳定性等)影响,会倾向于输出更平滑、更可行、更保守的轨迹,表现起来就是手臂运动幅度小。
优化方案:
执行
rosservice call /enable_wbc_arm_trajectory_control "control_mode: 1"
通过调用 /enable_wbc_arm_trajectory_control ROS 服务,启用 WBC(Whole Body Control,全身控制)手臂轨迹控制,即模型输出直接通过/kuavo_arm_traj 话题下发到
WBC控制器,手臂运动速度和精度都比原来要好上了很多。

由于推理频率与数转帧率对齐时,仅有10hz,跳过MPC优化后,下发给WBC的手臂运动频率过低,加速度过大,手臂运动抖动明显,需要在下发层添加帧间插值和低通滤波。
以上功能已集成进 kuavo_data_challenge dev分支 ,在 kuavo_env.yaml 中将direct_to_wbc参数改为 true 即可开启。具体调参说明可以参考具身智能数据处理与模型训练框架 - 资讯 - 乐聚 OpenLET 社区 4.3 模型输出与动作平滑
4. ACT推理策略优化
kuavo_deploy/eval_kuavo.py执行的real_single_test.py的核心是单线程串行:推理完一帧 → 执行一帧 → 再推理下一帧。推理耗时会直接占用控制周期。每步都要等 select_action() 完成才能 env.step(),虽然实时性较好,但表现起来比较卡顿。
增加异步推理脚本,把 推理 和 执行 拆成两个线程,用一个 动作缓冲队列衔接:
①推理线程 get_actions_async:只在 buffer 快空时触发推理,取一次观测 env.get_obs(),调用 policy.predict_action_chunk() 生成一段动作(chunk),后处理后把 chunk 写入 buffer
②执行线程 actor_control:不停从 buffer 取单步 action,立刻 env.step() 下发。
执行线程可以持续按节拍从 buffer 取动作下发;推理线程在后台补货,推理与执行重叠,调试得当可以消除停顿的现象,但异步也意味着“执行某一步动作时的观测”不一定是同一时刻采的,这是换取实时性的典型代价。其他策略部署推理也可以参考此脚本去适配实现异步推理。